目录
1. 站点模板爬虫概述
1.1 站点模板爬虫的工作原理
1.2 为什么选择Go语言
2. Go1.19的站点模板爬虫实现
2.1 环境配置
2.2 项目初始化
2.3 导入所需的库
2.4 获取网页内容
2.5 解析HTML内容
2.6 提取数据
2.7 主函数实现
2.8 完整代码
3. 常见挑战与解决方案
3.1 反爬虫机制
3.1.1 用户代理伪装
3.1.2 请求间隔
3.2 数据清洗
3.2.1 正则表达式
3.2.2 字符串处理
4. 高效爬虫策略
4.1 并发请求
4.2 去重机制
4.2.1 使用哈希表
4.2.2 使用布隆过滤器
5. 未来发展方向
5.1 人工智能辅助爬虫
5.2 分布式爬虫
结论
随着互联网的快速发展,数据的获取变得越来越重要。站点模板爬虫是一种高效的工具,能够自动化地从网页中提取有价值的信息。本文将介绍如何使用Go1.19编写一个高效的站点模板爬虫,包括其原理、代码实现以及常见的挑战和解决方案。
1. 站点模板爬虫概述
站点模板爬虫是一种能够自动访问网页并提取特定数据的程序。与一般的网页爬虫不同,站点模板爬虫专注于某类结构相似的网站,通过预定义的模板快速、准确地抓取所需的信息。
1.1 站点模板爬虫的工作原理
站点模板爬虫通过以下步骤工作:
- 获取网页内容:使用HTTP请求获取目标网页的HTML内容。
- 解析HTML内容:使用HTML解析库将HTML内容转换为可操作的DOM树。
- 提取数据:根据预定义的模板,从DOM树中提取所需的数据。
- 存储数据:将提取的数据存储到本地文件、数据库或其他存储介质中。
1.2 为什么选择Go语言
Go语言(简称Golang)因其高效、并发支持和简洁的语法,成为编写爬虫程序的理想选择。Go语言内置的并发模型使得处理大量HTTP请求变得更加简单和高效。此外,Go的强类型系统和标准库提供了丰富的网络和解析功能。
2. Go1.19的站点模板爬虫实现
下面我们将详细介绍如何使用Go1.19编写一个站点模板爬虫,涵盖从项目初始化到数据存储的各个方面。
2.1 环境配置
首先,确保你的系统中已经安装了Go1.19。可以通过以下命令检查Go版本:
go version
2.2 项目初始化
创建一个新的Go项目目录,并初始化Go模块:
mkdir go-web-scraper
cd go-web-scraper
go mod init go-web-scraper
2.3 导入所需的库
在main.go文件中,导入必要的库:
package main
import (
"fmt"
"log"
"net/http"
"io/ioutil"
"golang.org/x/net/html"
"strings"
)
需要安装golang.org/x/net/html库,用于解析HTML内容:
go get golang.org/x/net/html
2.4 获取网页内容
编写一个函数用于获取网页内容:
func fetchURL(url string) (string, error) {
resp, err := http.Get(url)
if err != nil {
return "", err
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
return "", err
}
return string(body), nil
}
2.5 解析HTML内容
使用golang.org/x/net/html库解析HTML内容:
func parseHTML(body string) (*html.Node, error) {
doc, err := html.Parse(strings.NewReader(body))
if err != nil {
return nil, err
}
return doc, nil
}
2.6 提取数据
编写一个函数从解析后的HTML中提取特定数据:
func extractData(node *html.Node, tag string, class string) []string {
var result []string
var f func(*html.Node)
f = func(n *html.Node) {
if n.Type == html.ElementNode && n.Data == tag {
for _, a := range n.Attr {
if a.Key == "class" && a.Val == class {
if n.FirstChild != nil {
result = append(result, n.FirstChild.Data)
}
break
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
f(c)
}
}
f(node)
return result
}
2.7 主函数实现
编写主函数,将以上步骤串联起来:
func main() {
url := "http://example.com"
body, err := fetchURL(url)
if err != nil {
log.Fatalf("Failed to fetch URL: %v", err)
}
doc, err := parseHTML(body)
if err != nil {
log.Fatalf("Failed to parse HTML: %v", err)
}
data := extractData(doc, "p", "example-class")
for _, item := range data {
fmt.Println(item)
}
}
2.8 完整代码
将所有代码整合到一个文件中:
package main
import (
"fmt"
"log"
"net/http"
"io/ioutil"
"golang.org/x/net/html"
"strings"
)
func fetchURL(url string) (string, error) {
resp, err := http.Get(url)
if err != nil {
return "", err
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
return "", err
}
return string(body), nil
}
func parseHTML(body string) (*html.Node, error) {
doc, err := html.Parse(strings.NewReader(body))
if err != nil {
return nil, err
}
return doc, nil
}
func extractData(node *html.Node, tag string, class string) []string {
var result []string
var f func(*html.Node)
f = func(n *html.Node) {
if n.Type == html.ElementNode && n.Data == tag {
for _, a := range n.Attr {
if a.Key == "class" && a.Val == class {
if n.FirstChild != nil {
result = append(result, n.FirstChild.Data)
}
break
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
f(c)
}
}
f(node)
return result
}
func main() {
url := "http://example.com"
body, err := fetchURL(url)
if err != nil {
log.Fatalf("Failed to fetch URL: %v", err)
}
doc, err := parseHTML(body)
if err != nil {
log.Fatalf("Failed to parse HTML: %v", err)
}
data := extractData(doc, "p", "example-class")
for _, item := range data {
fmt.Println(item)
}
}
3. 常见挑战与解决方案
3.1 反爬虫机制
很多网站都有反爬虫机制,如IP封禁、验证码等。以下是一些应对策略:
3.1.1 用户代理伪装
通过设置HTTP请求头中的用户代理,可以伪装成浏览器访问:
req, err := http.NewRequest("GET", url, nil)
if err != nil {
log.Fatalf("Failed to create request: %v", err)
}
req.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36")
client := &http.Client{}
resp, err := client.Do(req)
3.1.2 请求间隔
通过设置请求间隔,避免触发反爬虫机制:
import "time"
time.Sleep(2 * time.Second)
3.2 数据清洗
网页中的数据通常需要进行清洗和格式化,以便于后续处理。可以使用正则表达式或字符串处理函数进行数据清洗。
3.2.1 正则表达式
import "regexp"
re := regexp.MustCompile(`\s+`)
cleanedData := re.ReplaceAllString(rawData, " ")
3.2.2 字符串处理
cleanedData := strings.TrimSpace(rawData)
4. 高效爬虫策略
为了提高爬虫的效率,可以采用以下策略:
4.1 并发请求
使用Go的goroutine和channel,实现并发请求,提高抓取速度:
import (
"sync"
)
var wg sync.WaitGroup
ch := make(chan string)
func worker(url string, ch chan string) {
defer wg.Done()
body, err := fetchURL(url)
if err != nil {
log.Printf("Failed to fetch URL: %v", err)
return
}
ch <- body
}
func main() {
urls := []string{"http://example.com/1", "http://example.com/2", "http://example.com/3"}
for _, url := range urls {
wg.Add(1)
go worker(url, ch)
}
go func() {
wg.Wait()
close(ch)
}()
for body := range ch {
fmt.Println(body)
}
}
4.2 去重机制
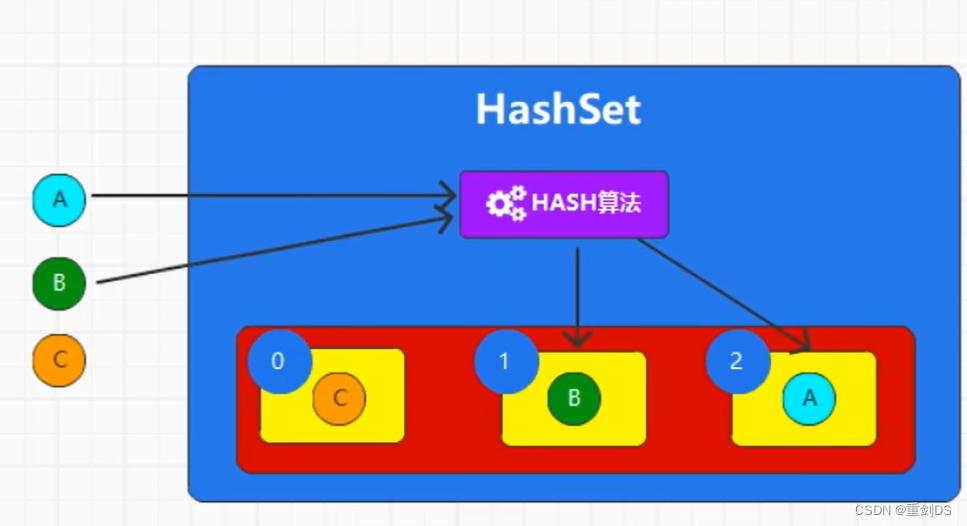
为了避免重复抓取相同的网页,需要实现去重机制。可以使用哈希表或布隆过滤器来存储已经抓取过的URL。
4.2.1 使用哈希表
visited := make(map[string]bool)
if !visited[url] {
visited[url] = true
// Fetch and process URL
}
4.2.2 使用布隆过滤器
布隆过滤器是一种高效的概率型数据结构,适用于大规模去重场景。可以使用第三方库实现布隆过滤器。
结论
基于Go1.19的站点模板爬虫是一种高效的数据抓取工具,能够帮助我们快速、准确地从网页中提取所需的信息。通过合理的设计和优化,可以应对反爬虫机制,提高抓取效率。未来,随着人工智能和分布式技术的发展,爬虫技术将更加智能和高效,为我们的数据获取和分析提供更强大的支持。